
機械学習モデルを作ったけど、「なぜこの予測が出たのか説明できない…」そんな経験はありませんか?
ブラックボックス化しがちな機械学習に透明性を与える手段として、いま注目されているのが「SHAP(シャップ)」です。
この記事では、SHAPの基本から、身近な例、Pythonコードを交えて、わかりやすく解説します!
目次
SHAPとは?
SHAP(SHapley Additive exPlanations)は、機械学習モデルの予測に対して、各特徴量(入力データ)がどれだけ影響を与えたかを数値化・可視化する方法です。
元々はゲーム理論の「シャープレーバリュー(Shapley value)」という考え方を応用しています。
簡単に言うと、
“この予測結果に対して、どの特徴量がどれくらい貢献したかを公平に分配する方法”
を提供してくれるのがSHAPです。
これにより、AIの予測に対して「なぜそうなったのか?」がわかり、透明性や信頼性を高めることができます。
身近な例でSHAPをイメージしよう
例えば、住宅価格を予測するモデルを考えてみましょう。
ある家の予測価格が3,000万円だとモデルが出したとき、SHAPを使うと次のように分解できます。
- 立地が良い:+800万円
- 延床面積が広い:+500万円
- 築年数が古い:-300万円
- 駅から遠い:-200万円
つまり、最終的に3000万円という結果になった理由が、「どの要素がプラスに働き、どの要素がマイナスだったのか」が一目瞭然になります。
これなら、家を売る側・買う側どちらも納得感がありますよね。
同じように、クレジットカードの審査や病気の診断モデルなどでも、SHAPを使えば「なぜこの結果になったのか?」を説明できるようになります。
SHAPの特徴
SHAPには大きく4つの特徴があります。
- 公平性:どの特徴量にも平等な立場で影響度を割り振る
- 一貫性:特徴量の影響が強くなれば、SHAP値も必ず増える
- 局所的説明:個々の予測に対して説明ができる
- モデル非依存:どんな機械学習モデルでも使える(ランダムフォレストでもXGBoostでもOK)
つまり、どんな場面でも柔軟に、かつ信頼できる形で説明ができるわけです!
PythonでSHAPを使ってみよう
では、実際にPythonコードでSHAPを使う例を紹介します。
ここでは、scikit-learnのデータセット「糖尿病データ(diabetes)」を使い、回帰モデルを解釈してみましょう。
必要なライブラリをインストール
pip install shap scikit-learn matplotlib
コード例
import shap
import numpy as np
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# データ読み込み
data = load_diabetes()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# 学習用とテスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデル学習
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)
# SHAP値の計算
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
# SHAP summary plot
shap.summary_plot(shap_values, X_test)
このコードを実行すると、特徴量ごとの重要度を色付きのプロットで確認できます!
出力イメージ
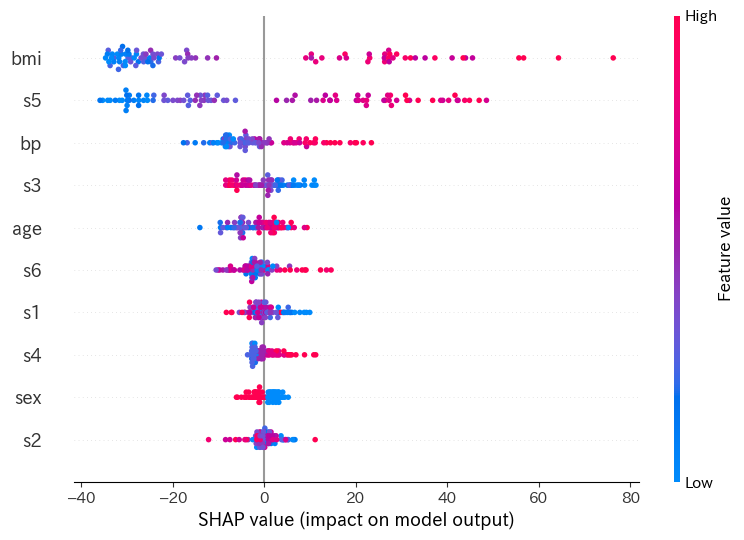
- 赤い点:特徴量が高い値を取った時の影響
- 青い点:特徴量が低い値を取った時の影響
特徴量ごとに、予測を押し上げたか押し下げたかが視覚的にわかります。
SHAPを使うメリット・デメリット
メリット
- モデルの透明性が上がる
- 関係者に説明しやすい(上司・クライアント向けにも◎)
- 不正確な予測の原因分析に使える
デメリット
- 計算コストが高い(特に大量データ、複雑モデルの場合)
- 全特徴量に対して計算するため、時間がかかる場合もある
とはいえ、最近は”TreeExplainer”のように高速化された手法もあるため、実用上はそこまで心配いりません。
まとめ:SHAPはこれからのAIに必須の技術!
SHAPは、「予測はできたけど理由がわからない」という機械学習の大きな課題を解決する強力なツールです。
特に、金融・医療・製造など、説明責任が求められる分野ではますます重要になっていくでしょう。
簡単におさらいすると:
- SHAPは予測の「なぜ?」を数値化・可視化する
- どんなモデルでも使えて、個別・全体両方の視点で分析できる
- Pythonで簡単に実装できる
今後、機械学習エンジニアだけでなく、ビジネスサイドの人たちにもSHAPの理解は必須になりそうです。
この記事の文字数:3926文字